
Voyage au cœur des technologies de fabrication pour la réalisation des futurs « systems of systems – on-chip », des systèmes embarqués et des objets connectés
En ce début de décennie, le domaine des system-on-chip, des systèmes embarqués et des objets connectés fait face à d’importants défis, pilotés essentiellement par la demande incessante de plus en plus de puissance de calcul et de capacité à traiter les informations, aussi bien au sein des system-on-chip qu’à l’échelle des systèmes interconnectés à grande échelle (IoE – Internet of Everything). Cet article va parcourir les nombreux axes de recherche en cours dans les laboratoires francais (CNRS) dans le cadre de l’action SOC2.*
En même temps, il y a un véritable renforcement de la prise de conscience des défis comme la consommation des ressources (énergie et matériaux), la fiabilisation et la sécurisation des systèmes et des données. De réelles opportunités émergent, sur le plan scientifique comme l’IA embarquée, mais aussi sur les plans contextuel et politique, comme le mouvement Open Hardware et les efforts de souveraineté numérique européenne.
Traditionnellement et depuis le début de l’ère de la microélectronique, l’augmentation de la puissance de calcul des processeurs s’est appuyée sur l’augmentation du nombre de transistors par unité de surface de silicium. C’est la Loi de Moore bien connue des économistes du domaine, et celle-ci continue encore, malgré quelques ralentissements dus en partie aux coûts très élevés de fabrication, mais aussi à l’atteinte de ruptures technologiques dans la réduction des échelles, qui nécessitent un gros travail de R&D au préalable, avec l’identification de nouveaux matériaux et de nouvelles techniques de fabrication toujours plus complexes. À titre d’exemple, les coûts de la fonderie TSMC Fab18 en Arizona aux États-Unis, qui cible la technologie cinq nanomètres - actuellement le processus le plus avancé en production – sont estimés à 12 milliards de dollars.
L’augmentation du nombre de composants élémentaires (More Moore) à disposition pour la réalisation de systèmes de calcul a conduit à l’émergence d’architectures multi-cœurs (manycore) pour paralléliser les calculs ou pour permettre leur traitement en parallèle, puis intégrer la montée en puissance des architectures impliquant des cœurs hétérogènes avec l’augmentation de leur taille et de leur complexité. Plusieurs laboratoires de l’axe « Calcul embarqué haute performance » du Groupement de Recherche SOC2 du CNRS explorent ces nouvelles architectures complexes et les problèmes de fonctionnement fiable sous-jacents.
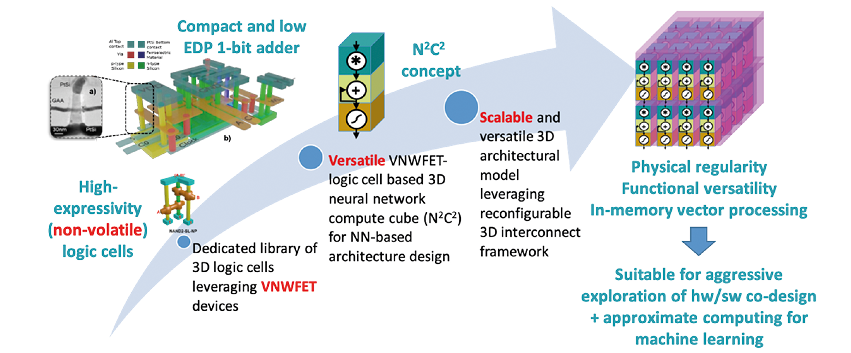
L’augmentation du nombre de transistors par puce s’appuie aussi sur la réduction des dimensions des transistors et nécessite de changements profonds à l’échelle de l’architecture même du transistor, qui évolueront des FinFETs planaires 2D d’aujourd’hui aux structures à grille entourante (Gate-All-Around). Mais cette augmentation de la complexité s’appuie également et de plus en plus sur la troisième dimension, par exemple l’empilement 3D monolithique tel que développé par le CEA-LETI à Grenoble. Cette tendance s’accentuera dans les années à venir. Notamment l’utilisation de transistors verticaux combine les deux approches en ouvrant la voie vers la réduction de la longueur de grille proche du nanomètre d’une part et vers l’empilement de plusieurs grilles sans augmenter l’empreinte latérale d’autre part. Cette technologie, développée par le LAAS à Toulouse, est au cœur d’un projet européen porté par IMS à Bordeaux et impliquant l’INL à Lyon, se concentrant sur la construction d’un « cube de calcul de réseau neuronal » très polyvalent qui peut être assemblé en trois dimensions pour permettre une mise en œuvre naturelle de réseaux de neurones. Les travaux préliminaires estiment que le produit énergie-délai (une mesure typique des performances de la technologie de calcul) peut être réduit d’un facteur d’au moins 10 par rapport aux technologies actuelles.
L’utilisation de composants hétérogènes comme technology booster pour augmenter la fonctionnalité des technologies CMOS gagne du terrain par rapport à la seule voie de réduction des dimensions. Cette approche s’appuie sur les recherches portant sur la co-intégration et l’intégration monolithique de technologies hétérogènes (More than Moore) de type MEMS, optique, fluidique, thermique…, amorcées il y a 30 ans et portées principalement par l’Europe depuis. Deux technologies de pointe en particulier émergent aujourd’hui : la photonique silicium et les mémoires non volatiles.
Les dispositifs de photonique silicium, fabriqués à l’aide des techniques de fabrication de semi-conducteurs existantes, permettent la création de dispositifs hybrides dans lesquels des composants photoniques et électroniques sont intégrés sur une seule puce. Cette technologie permet la création par exemple d’interconnexions optiques rendant possible le transfert de données plus rapide inter- et intra-puce dans des opérations critiques telles que les mises à jour de coefficients de réseaux de neurones par liens de diffusion entre les cœurs de calcul, exploré dans un projet national porté par l’INL et impliquant le CEA-LETI, les laboratoires C2N et IRISA, ainsi que la société Kalray. Un autre projet national, porté par le CEA-LETI et impliquant l’INL et l’ICB, s’appuie sur l’exploitation conjointe de la photonique silicium et des mémoires à changement de phase pour permettre des solutions naturellement adaptées à la réalisation efficace des opérations d’algèbre linéaire des modèles d’apprentissage machine (machine learning – ML) contemporains, telles que les multiplications matricielles dans les réseaux neuronaux profonds (deep neural networks – DNN) en utilisant des approches de calcul stochastique.
L’émergence de nouvelles technologies mémoire non volatiles (qui conservent les données même sans alimentation) à l’échelle nanométrique permet aussi de repenser la hiérarchie classique de mémorisation voire de remplacer les SRAM, les DRAM et les mémoires Flash traditionnelles dans les applications appropriées, par exemple en utilisant des mémoires compatibles CMOS telles que la RAM à changement de phase (PCRAM), la RAM résistive (ReRAM), la RAM magnétique (MRAM) ou les mémoires ferroélectriques (FeRAM ou FeFET). En effet, le principal inconvénient des approches conventionnelles réside dans le goulot d’étranglement du transport des données entre le processeur et la mémoire, qui nécessite des quantités d’énergie et du temps de plusieurs ordres de grandeur plus élevés qu’une seule opération de calcul. Les applications d’IA pour le traitement des données nécessitent des structures et des technologies de calcul avancées, au-delà de celles que l’on trouve couramment dans les processeurs ou les GPU modernes. Cela pousse physiquement le traitement des données vers les structures de la mémoire, suscitant des recherches sur le calcul proche mémoire (near memory computing - NMC) ou même en mémoire (in memory computing - IMC). Le prochain défi fondamental consiste à explorer les technologies émergentes de mémoire non volatiles pour répondre aux exigences de l’efficacité énergétique, de performances (latence et précision d’inférence) et de densité ultra-élevées des opérations de calcul d’IA de pointe. À l’INL, dans le cadre du projet de recherche européen 3eFerro, nous avons exploré l’utilisation de dispositifs ferroélectriques intégrés pour de nouveaux circuits logiques non volatils capables de stocker une fois pour toutes les coefficients DNN, puis d’exécuter les opérations nécessaires de multiplication et d’accumulation (somme des produits) des opérations sur les données à grande vitesse et uniquement lorsque cela est nécessaire, entraînant d’énormes économies d’énergie sans perte de performances.
À l’avenir, la mise à l’échelle de la technologie de traitement de l’information va nécessiter :
- De nouveaux paradigmes de calcul tels que le calcul neuromorphique ou le calcul quantique,
- De nouvelles architectures,
- Des percées technologiques au niveau des dispositifs utilisant :
- Des charges (par exemple, des transistors à faible pente sous le seuil), ou
- (à plus long terme) des variables d’état hybrides ou alternatives (par exemple spin, magnon, phonon, photon, électron-phonon, photon-supraconducteur qubit, photon-magnon) ; les états étant binaires (numériques), multi-niveaux, analogiques ou intriqués.
Dans une première approche, de telles techniques de fonctionnalité augmentée seront nécessairement couplées, en tant qu’accélérateurs de calcul, à des cœurs de calcul CMOS existants et nécessiteront des techniques d’intégration hétérogènes extrêmes. Il existe une grande variété de techniques d’intégration, à des échelles diverses. Il s’agit de tirer profit de ces techniques – en effet, l’intégration 3D monolithique homogène ou hétérogène au niveau de la puce, ou l’intégration 2.5D hétérogène au niveau du packaging (empilement vertical, ou approche des chiplets) ne sont que des outils à sélectionner au cas par cas pour optimiser les performances du système et minimiser les coûts. Ainsi, cela rajoute un levier supplémentaire (et donc un degré de complexité supplémentaire) à la conception de ces systèmes déjà très complexes. Il est donc crucial, avec une telle complexité sans précédent, de maîtriser l’hétérogénéité des systèmes via des méthodes de conception performantes à tous les niveaux : technologique, architectural, et logiciel. Cet objectif, à visée clairement multi-niveaux, joue un rôle absolument central dans la définition de solutions. En effet, grâce aux leviers spécifiques offerts par chaque paradigme de calcul, architecture et technologie, diverses problématiques en jeu pour l’avènement de systèmes à la fois performants, efficaces en énergie et prédictibles seront plus aisément adressables.
Au travers de cet article, vous aurez ainsi compris que les composants de demain vont nécessiter beaucoup de travaux de recherche et de développement des technologies de fabrication, avec de multiples défis à résoudre pour la communauté des chercheurs et des ingénieurs, au niveau mondial.
Référence
* https://www.gdr-soc.cnrs.fr
 Ian O’Connor
Ian O’Connor
est professeur de systèmes nanoélectroniques et hétérogènes dans le département d’électronique, électrotechnique et automatique à l’École Centrale de Lyon. Il donne des cours en cycle ingénieur sur les systèmes électroniques avancés, les microsystèmes autonomes, le calcul haute performance et les circuits micro-nanoélectroniques. Il est actuellement responsable de l’équipe conception de systèmes hétérogènes à l’Institut des Nanotechnologies de Lyon (INL) ainsi que directeur du Groupement de Recherche SOC2 (Systems on Chip, Systèmes embarqués et Objets Connectés). Depuis 2008, il est également titulaire d’un poste de professeur associé à l’École polytechnique de Montréal, Canada. Ses travaux de recherche portent sur les nouvelles architectures de calcul et d’interconnexion basées sur les technologies émergentes, associées aux méthodes de conception et d’exploration. Il est auteur ou co-auteur de plus de 250 livres, articles de journal, articles de conférence et brevets, a occupé divers postes de responsabilité dans l’organisation de plusieurs conférences internationales et a été coordinateur scientifique de plusieurs projets nationaux et européens. Il est également expert auprès de l’IFIP (International Federation for Information Processing) WG10.5 (Design and Engineering of Electronic Systems), et il est Vice-Président pour Initiatives auprès de l’IEEE Council for Electronic Design Automation (CEDA). Il a également été expert auprès de l’Observatoire des micro et nanotechnologies (OMNT) et de l’Alliance pour les sciences et technologies du numérique (Allistene).
Auteur
Articles du numéro
-
- L’Intelligence Artificielle et les puces électroniquesL’Intelligence Artificielle et les puces électroniques L’intelligence Artificielle est le thème porteur auprès des jeunes générations sortant des écoles...29 juin 2022Lire la suite >
-
- LA NUMÉRISATION 3D, technologies et applicationsLA NUMÉRISATION 3D, technologies et applications Cela fait bien des années déjà que nous pouvons constater la prolifération des capteurs...29 juin 2022Lire la suite >
-
- Les micro et nano technologies au service de la décarbonation du monde pétrolierLes micro et nano technologies au service de la... Publirédactionnel Schlumberger Schlumberger a récemment annoncé son engagement de neutralité...29 juin 2022Lire la suite >
-
- La sécurité, un enjeu majeur pour les équipements connectés !La sécurité, un enjeu majeur pour les équipements connectés... Le déploiement à grande échelle d’objets communicants au sein de nos systèmes de la vie quotidienne...29 juin 2022Lire la suite >
-
- ENTRETIEN : Dans la peau d’une Deeptech du semi-conducteurENTRETIEN : Dans la peau d’une Deeptech du semi-conducteur Entretien avec Eric Baissus (1995), Président du Directoire de Kalray Pouvez-vous nous présenter...29 juin 2022Lire la suite >
-
- Metaverse A Silicon Valley ViewMetaverse A Silicon Valley View What is the metaverse ? The term metaverse means different things depending on who you ask. Whilst...29 juin 2022Lire la suite >
-
- Eagle : Le processeur d’IBM qui passe la barrière des 100 qubitEagle : Le processeur d’IBM qui passe la barrière des 100... Le 16 novembre dernier, IBM organisait l’IBM Quantum Summit 2021, un événement annuel pour les...29 juin 2022Lire la suite >
-
- LoRaWAN : une technologie IoT basse consommation pour l’optimisation des productions et des usagesLoRaWAN : une technologie IoT basse consommation pour... Dans le domaine de l’internet des objets, la technologie LoRa® fournit un des composants essentiels...29 juin 2022Lire la suite >
-
- L’hybridation des réseaux terrestre / satellitaire dans le tracking via une balise hybride intelligenteL’hybridation des réseaux terrestre / satellitaire dans le... Le tracking est une composante essentielle dans la chaîne logistique. Pour avoir une couverture...29 juin 2022Lire la suite >
-
- Acklio Story, histoire d’une start-up de l’IOT par ses membres fondateursAcklio Story, histoire d’une start-up de l’IOT par ses... Alexander Pelov et Laurent Toutain, cofondateurs d’Acklio, alors chercheurs à IMT Atlantique, pour...29 juin 2022Lire la suite >
-
- MIMOPT Technology : La genèseMIMOPT Technology : La genèse MIMOPT Technology est une spin-off de Télécom Paris créée en avril 2021 par deux professeurs de...29 juin 2022Lire la suite >
-
- To make the world a place with strong security, privacy and digital ownership for allTo make the world a place with strong security, privacy and... VALDIMO is a star-tup created in April 2021 and incubated at the Télécom Paris incubator. Valmido...29 juin 2022Lire la suite >
-
- RocqStaT, un produit StatInf, lauréat aux Trophées des Assises de l’EmbarquéRocqStaT, un produit StatInf, lauréat aux Trophées des... StatInf, spin-off de l’Inria, au cœur de l’innovation technologique StatInf est l’aboutissement des...29 juin 2022Lire la suite >
-
- Le développement du cerveau à l’ère numériqueLe développement du cerveau à l’ère numérique La notion de norme intellectuelle, et plus globalement cognitive, est en constante évolution car...29 juin 2022Lire la suite >
-
- Numérique et esprit critique ? Le regard de la psychologie socialeNumérique et esprit critique ? Le regard de la psychologie... Depuis longtemps, l’apport des technologies à l’homme et à l’humanité est un objet de débats. Une...29 juin 2022Lire la suite >
-
- Les bulles communicationnelles et la fracture socialeLes bulles communicationnelles et la fracture sociale (avec l’aimable participation de Jacques Guyard et de Jean-Stéphane Migot) La question peut...29 juin 2022Lire la suite >
-
- Des technologies durables au bénéfice de la société et de l’environnementDes technologies durables au bénéfice de la société et de... Il est temps de changer de paradigme. L’urgence climatique et les conséquences du numérique sur nos...29 juin 2022Lire la suite >
-
- Innover, réparer, subsisterInnover, réparer, subsister L’élan donné par l’innovation technologique a porté le développement des technologies numériques...29 juin 2022Lire la suite >



















